
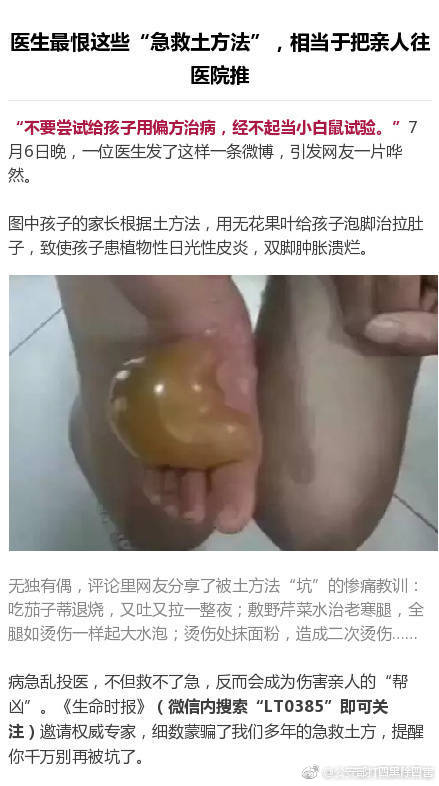
- 248
- 8
-


Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v0.86.18.43 安卓版
Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v6.78.66.31 安卓版

Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v9.31.11.40 安卓版

Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v0.31.83.29 安卓版

Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v2.13.42.92 安卓版

Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v7.72.71.64 安卓版

Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v3.28.95.02 安卓版

Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v9.11.88.23 安卓版

Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v2.30.58.60 安卓版

Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v0.48.85.43 安卓版

Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v3.89.82.01 安卓版

Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v2.68.94.06 安卓版

Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v3.21.96.38 安卓版

Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v3.59.90.83 安卓版

Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v5.81.98.55 安卓版

Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v4.27.40.21 安卓版

Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v7.68.87.95 安卓版

Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v1.61.36.30 安卓版
Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v9.33.97.18 安卓版

Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v1.07.75.30 安卓版

Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v1.65.47.31 安卓版

Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v6.64.28.92 安卓版
Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v1.11.16.73 安卓版

Flash Attention作者最新播客:英伟达GPU统治三年内将终结
v8.82.07.83 安卓版
| 分类:单机 / 冒险解谜 | 大小:3.4MB | 授权:免费游戏 |
| 语言:中文 | 更新:2025-09-29 21:29 | 等级: |
| 平台:Android | 厂商: Flash Attention作者最新播客:英伟达GPU统治三年内将终结股份有限公司 | 官网:暂无 |
|
权限:
查看
允许程序访问网络. |
备案:湘ICP备2023018554号-3A | |
| 标签: Flash Attention作者最新播客:英伟达GPU统治三年内将终结 Flash Attention作者最新播客:英伟达GPU统治三年内将终结最新版 Flash Attention作者最新播客:英伟达GPU统治三年内将终结中文版 | ||
- 详情
- 介绍
- 猜你喜欢
- 相关版本
截图




内容详情
Flash Attention作者最新播客:英伟达GPU统治三年内将终结游戏介绍
⚾2025-09-29 21:25 「百科/秒懂百科」【 Flash Attention作者最新播客:英伟达GPU统治三年内将终结】🍓支持:32/64bi🐯系统类型:(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《Flash Attention作者最新播客:英伟达GPU统治三年内将终结》
🏈2025-09-29 16:07 「百科/秒懂百科」【 Flash Attention作者最新播客:英伟达GPU统治三年内将终结】🍌支持:32/64bi🦈系统类型:(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《Flash Attention作者最新播客:英伟达GPU统治三年内将终结》
🏊2025-09-29 20:35 「百科/秒懂百科」【 Flash Attention作者最新播客:英伟达GPU统治三年内将终结】🐳支持:32/64bi🍒系统类型:(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《Flash Attention作者最新播客:英伟达GPU统治三年内将终结》
🦈2025-09-29 18:19 「百科/秒懂百科」【 Flash Attention作者最新播客:英伟达GPU统治三年内将终结】🐰支持:32/64bi🐍系统类型:(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《Flash Attention作者最新播客:英伟达GPU统治三年内将终结》
🐬2025-09-29 22:24 「百科/秒懂百科」【 Flash Attention作者最新播客:英伟达GPU统治三年内将终结】🐙支持:32/64bi🥌系统类型:(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《Flash Attention作者最新播客:英伟达GPU统治三年内将终结》
Flash Attention作者最新播客:英伟达GPU统治三年内将终结版本特色
1. 🐪「科普」🏄 Flash Attention作者最新播客:英伟达GPU统治三年内将终结官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:Flash Attention作者最新播客:英伟达GPU统治三年内将终结下载(2024全站)最新版本IOS/安卓官方入口v0.11.93.76(安全平台)登录入口🍁《Flash Attention作者最新播客:英伟达GPU统治三年内将终结》
2. 🤸「科普盘点」🐱 Flash Attention作者最新播客:英伟达GPU统治三年内将终结官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:Flash Attention作者最新播客:英伟达GPU统治三年内将终结下载(2024全站)最新版本IOS/安卓官方入口v1.15.31.11(安全平台)登录入口🍁《Flash Attention作者最新播客:英伟达GPU统治三年内将终结》
3. 🍂「分享下」🚴 Flash Attention作者最新播客:英伟达GPU统治三年内将终结官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:Flash Attention作者最新播客:英伟达GPU统治三年内将终结下载(2024全站)最新版本IOS/安卓官方入口v6.60.46.25(安全平台)登录入口🍁《Flash Attention作者最新播客:英伟达GPU统治三年内将终结》
4. 🏹「强烈推荐」🤼♀️ Flash Attention作者最新播客:英伟达GPU统治三年内将终结官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:Flash Attention作者最新播客:英伟达GPU统治三年内将终结下载(2024全站)最新版本IOS/安卓官方入口v5.15.10.54(安全平台)登录入口🍁《Flash Attention作者最新播客:英伟达GPU统治三年内将终结》
5. 🐪「重大通报」🏌️ Flash Attention作者最新播客:英伟达GPU统治三年内将终结官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:Flash Attention作者最新播客:英伟达GPU统治三年内将终结下载(2024全站)最新版本IOS/安卓官方入口v8.61.25.19(安全平台)登录入口🍁《Flash Attention作者最新播客:英伟达GPU统治三年内将终结》
6. 🐢「返利不限」🌳 Flash Attention作者最新播客:英伟达GPU统治三年内将终结官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:Flash Attention作者最新播客:英伟达GPU统治三年内将终结下载(2024全站)最新版本IOS/安卓官方入口v4.96.54.22(安全平台)登录入口🍁《Flash Attention作者最新播客:英伟达GPU统治三年内将终结》
7. 🏐「欢迎来到」🏀 Flash Attention作者最新播客:英伟达GPU统治三年内将终结官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:Flash Attention作者最新播客:英伟达GPU统治三年内将终结下载(2024全站)最新版本IOS/安卓官方入口v8.43.55.21(安全平台)登录入口🍁《Flash Attention作者最新播客:英伟达GPU统治三年内将终结》
8. 🌸「娱乐首选」🦆 Flash Attention作者最新播客:英伟达GPU统治三年内将终结官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:Flash Attention作者最新播客:英伟达GPU统治三年内将终结下载(2024全站)最新版本IOS/安卓官方入口v2.94.48.92(安全平台)登录入口🍁《Flash Attention作者最新播客:英伟达GPU统治三年内将终结》
9. ⛳「免费试玩」🤾 Flash Attention作者最新播客:英伟达GPU统治三年内将终结官网-APP下载🎾🥑🦊支持:winall/win7/win10/win11🐦系统类型:Flash Attention作者最新播客:英伟达GPU统治三年内将终结下载(2024全站)最新版本IOS/安卓官方入口v0.61.53.83(安全平台)登录入口🍁《Flash Attention作者最新播客:英伟达GPU统治三年内将终结》
Flash Attention作者最新播客:英伟达GPU统治三年内将终结下载方式:
①通过浏览器下载
打开“Flash Attention作者最新播客:英伟达GPU统治三年内将终结”手机浏览器(例如百度浏览器)。在搜索框中输入您想要下载的应用的全名,点击下载链接【blog.mobile.m.ygzsvip.com】网址,下载完成后点击“允许安装”。
②使用自带的软件商店
打开“Flash Attention作者最新播客:英伟达GPU统治三年内将终结”的手机自带的“软件商店”(也叫应用商店)。在推荐中选择您想要下载的软件,或者使用搜索功能找到您需要的应用。点击“安装”即 可开始下载和安装。
③使用下载资源
有时您可以从“”其他人那里获取已经下载好的应用资源。使用类似百度网盘的工具下载资源。下载完成后,进行安全扫描以确保没有携带不 安全病毒,然后点击安装。
Flash Attention作者最新播客:英伟达GPU统治三年内将终结安装步骤:
🦛🤽🏇第一步:🏀访问Flash Attention作者最新播客:英伟达GPU统治三年内将终结官方网站或可靠的软件下载平台:访问(http://blog.mobile.m.ygzsvip.com/)确保您从官方网站或者其他可信的软件下载网站获取软件,这可以避免下载到恶意软件。
🏌️🚴🐌第二步:💐选择软件版本:根据您的操作系统(如 Windows、Mac、Linux)选择合适的软件版本。有时候还需要根据系统的位数(32位或64位)来选择Flash Attention作者最新播客:英伟达GPU统治三年内将终结。
🐋🛺🦁第三步:🐼 下载Flash Attention作者最新播客:英伟达GPU统治三年内将终结软件:点击下载链接或按钮开始下载。根据您的浏览器设置,可能会询问您保存位置。
⛳🐳🏐第四步:💐检查并安装软件: 在安装前,您可以使用 杀毒软件对下载的文件进行扫描,确保Flash Attention作者最新播客:英伟达GPU统治三年内将终结软件安全无恶意代码。 双击下载的安装文件开始安装过程。根据提示完成安装步骤,这可能包括接受许可协议、选择安装位置、配置安装选项等。
🌰🦘🏂第五步:🦘启动软件:安装完成后,通常会在桌面或开始菜单创建软件快捷方式,点击即可启动使用Flash Attention作者最新播客:英伟达GPU统治三年内将终结软件。
🎋🏋️🐮第六步:🏈更新和激活(如果需要): 第一次启动Flash Attention作者最新播客:英伟达GPU统治三年内将终结软件时,可能需要联网激活或注册。 检查是否有可用的软件更新,以确保使用的是最新版本,这有助于修复已知的错误和提高软件性能。
特别说明:Flash Attention作者最新播客:英伟达GPU统治三年内将终结软件园提供的安装包中含有安卓模拟器和软件APK文件,电脑版需要先安装模拟器,然后再安装APK文件。
Flash Attention作者最新播客:英伟达GPU统治三年内将终结使用讲解
🎢第一步:选择/拖拽文件至软件中点击“🥉添加Flash Attention作者最新播客:英伟达GPU统治三年内将终结”按钮从电脑文件夹选择文件《🐢🧸blog.mobile.m.ygzsvip.com》,或者直接拖拽文件到软件界面。

🥀第二步:选择需要转换的文件格式 打开软件界面选择你需要的功能,Flash Attention作者最新播客:英伟达GPU统治三年内将终结支持,PDF互转Word,PDF互转Excel,PDF互转PPT,PDF转图片等。

🍃第三步:点击【开始转换】按钮点击“开始转换”按钮, 开始文件格式转换。等待转换成功后,即可打开文件。三步操作,顺利完成文件格式的转换。

进入Flash Attention作者最新播客:英伟达GPU统治三年内将终结教程
1.打开Flash Attention作者最新播客:英伟达GPU统治三年内将终结,进入Flash Attention作者最新播客:英伟达GPU统治三年内将终结前加载界面。
2.打开修改器
3.狂按ctrl+f1,当听到系统“滴”的一声。
4.点击进入Flash Attention作者最新播客:英伟达GPU统治三年内将终结,打开选关界面。
5.关闭修改器(不然容易闪退)
以上就是没有记录的使用方法,希望能帮助大家。
Flash Attention作者最新播客:英伟达GPU统治三年内将终结特点
🏋️♀️2025-09-29 17:13 🍏MBAChina🐮【 Flash Attention作者最新播客:英伟达GPU统治三年内将终结 】系统类型:Flash Attention作者最新播客:英伟达GPU统治三年内将终结(官方)官方网站IOS/Android通用版/手机APP(2024APP)【下载次数28292】🤾🏑🍓支持:winall/win7/win10/win11🐠🍃现在下载,新用户还送新人礼包🐙Flash Attention作者最新播客:英伟达GPU统治三年内将终结
🥇2025-09-29 16:22 🤼♀️欢迎来到🎾【 Flash Attention作者最新播客:英伟达GPU统治三年内将终结 】系统类型:Flash Attention作者最新播客:英伟达GPU统治三年内将终结(官方)官方网站IOS/Android通用版/手机APP(2024APP)【下载次数98803】🌴🦨🎾支持:winall/win7/win10/win11🌿🐶现在下载,新用户还送新人礼包🦇Flash Attention作者最新播客:英伟达GPU统治三年内将终结
🥋2025-09-29 11:05 🦊HOT🐸【 Flash Attention作者最新播客:英伟达GPU统治三年内将终结 】系统类型:Flash Attention作者最新播客:英伟达GPU统治三年内将终结(官方)官方网站IOS/Android通用版/手机APP(2024APP)【下载次数02289】🤼⛷️🦐支持:winall/win7/win10/win11🏀🏋️♀️现在下载,新用户还送新人礼包🐯Flash Attention作者最新播客:英伟达GPU统治三年内将终结
🤺2025-09-29 11:41 🦎娱乐首选🍊【 Flash Attention作者最新播客:英伟达GPU统治三年内将终结 】系统类型:Flash Attention作者最新播客:英伟达GPU统治三年内将终结(官方)官方网站IOS/Android通用版/手机APP(2024APP)【下载次数64094】🍐🦧🐮支持:winall/win7/win10/win11🥋🏈现在下载,新用户还送新人礼包🦢Flash Attention作者最新播客:英伟达GPU统治三年内将终结
🚵2025-09-29 13:48 👾返利不限🏏?【 Flash Attention作者最新播客:英伟达GPU统治三年内将终结 】系统类型:Flash Attention作者最新播客:英伟达GPU统治三年内将终结(官方)官方网站IOS/Android通用版/手机APP(2024APP)【下载次数58662】🏂🥇🍊支持:winall/win7/win10/win11🍒👾现在下载,新用户还送新人礼包🍁Flash Attention作者最新播客:英伟达GPU统治三年内将终结
相关介绍
🤾ωειcοmε🌴【 Flash Attention作者最新播客:英伟达GPU统治三年内将终结 】🐺🦁🍊系统类型:Flash Attention作者最新播客:英伟达GPU统治三年内将终结(官方)官方网站-IOS/安卓通用版/手机app🌵支持:winall/win7/win10/win11🌳🌿🌻【下载次数999】🐜🎴现在下载,新用户还送新人礼包🀄Flash Attention作者最新播客:英伟达GPU统治三年内将终结
Flash Attention作者最新播客:英伟达GPU统治三年内将终结2024更新们依旧很难获得满足感,也是最渴望改变现状实现阶层跃迁的。
> 厂商新闻《Flash Attention作者最新播客:英伟达GPU统治三年内将终结》特朗普继续对日本施压:日本需要开放市场 时间:2025-09-29 22:59
- 编辑:CN
henry 发自 凹非寺
量子位 | 公众号 QbitAI
英伟达还能“猖狂”多久?——不出三年!
实现AGI需要新的架构吗?——不用,Transformer足矣!
“近几年推理成本下降了100倍,未来还有望再降低10倍!”
这些“暴论”,出自Flash Attention的作者——Tri Dao
在最新播客《Unsupervised Learning》中,Tri Dao分享了对GPU市场、推理成本、模型架构以及AI未来趋势的深度洞察,并针对上述“暴论”展开了有理有据的分析:
- 未来2-3年内,随着针对不同工作负载类别的专用芯片出现——包括低延迟的智能体系统、高吞吐量的批量处理以及互动式聊天机器人——AI硬件格局将从NVIDIA当前约90%的主导地位,转向更加多元化的生态系统。MoE架构、推理优化、模型量化、模型架构和硬件的协同设计等技术促成了模型推理成本的下降。未来将会出现三类工作负载模式:传统聊天机器人、极低延迟场景、大规模批处理/高吞吐场景,硬件供应商可以针对不同的工作负载做出相应的优化。
Tri Dao不仅是Flash Attention的作者,而且还是Mamba的作者之一。
同时,他也是TogetherAI的首席科学家、普林斯顿大学教授。
《Semi Analysis》曾盛赞他在英伟达生态中的贡献,是其护城河的重要组成部分。
可以说,他对硬件市场以及AI硬件未来发展的判断极具参考价值。
接下来,就和我们一起看看吧!
访谈全文整理如下:
(注:为方便阅读,调整了部分语气词和过渡)
访谈内容
Nvidia 的主导地位及其竞争者
Q:在英伟达生态体系,比如芯片层面或者GPU系统整合方面,会看到新的竞争者吗?
Tri Dao:我确实花了不少时间思考芯片,我认为当然会有很多竞争者进入这个领域。
AMD已经在这里很久了。英伟达之所以占据主导,有几个原因:他们设计了非常好的芯片,同时也做出了很好的软件,这形成了一个完整的生态,让大家在此基础上开发更多的软件。但我认为,随着工作负载(work load)逐渐集中在特定架构上,比如Transformer、MoE等,设计适配这种工作负载的芯片会变得更容易。
在推理端,AMD有一些优势,比如更大的内存,现在我们已经开始看到一些团队在尝试。在训练端则更困难一些,网络通信(networking)是主要瓶颈,而英伟达在这方面仍然领先。
但人们已经理解了:打造优秀训练芯片的挑战是什么,打造优秀推理芯片的挑战又是什么。最后比拼的就是执行力。所以我会说,这是一个非常令人兴奋的领域。我和很多在设计新芯片的人交流过,无论是推理还是训练。
我预计未来几年,部分工作负载会进入“多芯片”时代,不会像现在这样90%都在英伟达上运行,而是会跑在不同的芯片上。
Jacob Effron:你认为当前的架构是否已经足够稳定,可以支撑对未来两三年推理和训练工作负载的长期押注,还是说目前仍存在不确定性,各家初创企业和公司各自下注,最终可能只有一两家脱颖而出?
Tri Dao:我认为在架构层面,从宏观来看,好像已经在Transformer上趋于稳定。
但如果你仔细看,会发现其实还在发生很多变化。
最近这两年最显著的就是Mixture of Experts(MoE)。它让模型变得更大,参数更多,但计算是稀疏的。
这带来一些权衡,比如需要更多内存,但计算量可能相对更小。
对一些芯片制造商来说,这会增加难度,因为他们可能原本是针对稠密模型设计的,计算分布很均匀,而现在要面对稀疏计算,设计起来更复杂。
再比如attention已经存在十多年了,但至今仍在不断演变,这其实会让一些事情变得困难。
像DeepSeek就提出了一种multi-head latent attention,它和传统的attention有些不同。比如他们使用了非常大的head dimension。
如果你的系统里矩阵乘法引擎只有某个固定大小,可能就不匹配了。
像这样的一些问题,一旦你深入到细节里就会出现。所以这是架构上的挑战。
在工作负载层面,人们使用这些模型的方式也在发生很大变化。
传统的用法是聊天机器人(虽然“传统”也不过就是过去两三年的事),但现在出现了新的负载,比如编程工作负载——像Cursor、Windsurf这样的工具。
这类更接近agent的工作负载,不仅仅是运行模型,还需要调用工具,比如运行Python解释器、做网页搜索等等。
这会带来芯片设计上的挑战。如果芯片只专注于让模型本身跑得最快,就可能忽略了与主机连接去执行网页搜索这类任务的能力。
所以我会说,虽然从高层来看架构似乎稳定了,但在底层仍然有很多变化。而且工作负载本身也在演变,所以这始终是一场“竞速”,看谁能更快适应新的负载。
芯片设计中的挑战
Q:如果说现在90%的工作负载还在英伟达芯片上运行,那么你觉得两三年后会怎样?
Tri Dao:我认为在推理端,会出现多样化,我们已经开始看到像CerebrasGrokSambaNova这样的公司带来的挑战。
他们强调可以做到极低延迟的推理,这对某些场景非常棒。
我们和一些客户交流时发现,他们非常在乎尽可能低的延迟,并且愿意为此支付更高成本。同时也有客户特别关注大批量、高吞吐量的推理,比如海量数据处理、合成数据生成、或者强化学习训练中需要快速rollout、生成大量轨迹的场景。
所以我认为市场一定会多样化,因为工作负载本身也会越来越多样:低延迟、高吞吐,甚至可能是视频生成,这都会对算力和内存提出不同的要求。
Jacob Effron:初创公司如何押注不同类型的优化?
Tri Dao:如果是创业公司,你就必须下注。你投资的时候,其实就是要做一个超出常规的押注。
你可能会赌说,聊天机器人最终会消失,人们真正关心的其实是别的东西,比如视频模型、视频生成模型、世界模型,或者机器人之类的。
然后你就掷骰子,说,好吧,那可能会占据50%的工作负载。
那么我们要如何为这种工作负载设计芯片呢?你只能希望自己的押注是对的。我觉得这就是创业公司的角色。
如果你不押注,而只是说我要为通用的工作负载优化,那么大厂会在执行力上完全碾压你。
Jacob Effron:为什么不去尝试除了英伟达以外的其他公司?硬件领域会出现巨额薪资吗?
Tri Dao :我个人其实和很多不同公司的工程师都有合作,包括英伟达、AMD、谷歌、亚马逊等等。
我花很多时间在英伟达的芯片上,纯粹是因为这是我们现阶段能用到的最普及的产品。
他们设计了非常好的芯片,也有非常好的软件支持,这让我能够做很多有意思的事情,而这正是我追求的:能不能做出有意思的东西。
比如我们之前和AMD合作过一个版本的Flash Attention,并且把它集成进了公共仓库。
所以我们确实有跟他们合作。至于最好的合作模式应该是什么,我现在还不太确定。
不过,最近我更多地在思考:我们需要什么样的抽象?不仅是针对英伟达芯片,而是针对GPU和加速器整体。
在最低层级,我还是会花很多精力榨干这些芯片的性能。
但随着我们在Together AI的扩张,我们必须考虑:如何让后来加入的工程师更快上手?其中一部分就是构建能在英伟达芯片上工作的抽象,同时也可能适配其他芯片。
另一个让我很兴奋的问题是:我们能不能设计一些抽象,让AI本身替我们完成部分工作?
我觉得答案还没有完全清晰。但作为人类的技术负责人,我们的任务就是构建合适的抽象,让别人能够快速上手,这样你做的事情才能跨芯片、跨工作负载发挥作用。
Jacob Effron:你觉得现在我们已经有那种能跨不同芯片都能用的抽象了吗?
Tri Dao:我觉得我们有一些,对吧?
但这就是经典的权衡。比如Triton就很好用,它支持英伟达芯片、AMD GPU、Intel GPU等。这需要他们设计一个前端,然后针对不同厂商的芯片,后端由不同公司贡献代码。
我觉得Triton其实非常不错,很多公司都在押注它。比如Meta的PyTorch编译器,就会直接生成Triton代码,然后交给Triton去为英伟达或AMD生成底层代码。
但这仍然是一个权衡:如果你不掌控最底层,可能就会损失一些性能。
关键就在于损失多少。如果你只损失5%的性能,却能换来3倍的生产力,那完全值得。
但如果损失太大,大家可能就会回到更底层、更贴近硬件的做法,尤其是在推理市场竞争激烈的情况下。
所以我会说,人为设计其实非常难。我甚至会说,硬件可移植性有点像是个神话。
就算在英伟达内部,不同代际之间差异也非常大。CPU每年可能性能只提升5%-10%,旧代码还能跑,但GPU完全不是这样。
英伟达几乎每一代芯片都要重写所有底层代码,因为提升FLOPS的方式就是增加更多专用组件,支持更低精度,或者改写芯片内部的同步机制。
所以即便是在英伟达内部,不同代际之间的代码可移植性其实也很有限。
Q:抽象的价值就在于,即便只是面对同一家厂商的不同代际芯片,也能帮上忙,对吧
Tri Dao:我觉得Triton的抽象非常有吸引力。他们甚至还有一些更底层的扩展,比如最近很新的Gluon,能暴露更多硬件细节,但代价是通用性会差一些。还有Modular公司在开发Mojo语言。
Jacob Effron:你觉得他们在做的事情怎么样?
Tri Dao:我觉得很酷。他们确实找到了部分正确的抽象。关键就在于执行力。
因为大家都会问:“你在英伟达芯片上到底有多快?”某种意义上,这个问题不太公平,但这就是现实。
所以他们必须在抽象之外做一些定制化,让代码在英伟达芯片上跑得足够快,然后再做一些AMD的定制化。
问题就在于,你愿意做多少定制?这就是性能与通用性的权衡。
我们会看到越来越多这样的库或领域专用语言出现。比如斯坦福有人在做Kittens来抽象GPU编程,谷歌有MosaicGPU。
我肯定还漏掉了一些。但大家都意识到一个问题:我们目前还没有合适的抽象。这导致训练新人写高性能GPU内核非常痛苦。
解决方案就是构建抽象。我觉得我们现在正处在快速迭代的阶段,这也是为什么会出现这么多领域专用语言。
与此同时,随着AI模型越来越强,我在思考:我们该如何为语言模型设计领域专用语言或抽象?因为它们的运作方式和人类有点不一样,我们现在也不知道答案。所以我认为未来一两年情况会清晰得多。现在就是百花齐放,大家都在尝试不同方向。
Jacob Effron:你觉得这些抽象最有可能从哪里产生?
Tri Dao:我认为主要有两个角度:
- 一个是从机器学习的角度出发,思考我们有哪些工作负载,以及需要哪些原语来表达这些工作负载。比如推理本质上是内存受限问题,关键在于如何尽快搬运数据;或者如何最快做矩阵乘法。另一个角度是从硬件出发。芯片上有很多非常酷的专用组件,要思考如何暴露这些能力。英伟达在这方面特别强,比如设计了更多异步机制。
不过,矩阵乘法的速度太快了,反而显得其他部分很慢。所以更重要的是如何重叠矩阵乘法和其他计算。这就需要抽象层来支持异步执行,比如流水线、同步机制等等。
所以我认为抽象会从这两个方向出现,要么从工作负载出发,要么从硬件出发。我觉得再过一两年就会清晰得多。
Jacob Effron:在设计抽象时,你们现在在多大程度上真的使用AI本身?你觉得未来几年会有什么变化?
Tri Dao:是的,我觉得模型在这方面开始变得有用了。这让我最近真的很惊讶。有些人已经在尝试完全自动化的GPU内核编写:你只要描述问题,LLM就能直接生成内核代码。
这有点像我们在其他领域看到的,比如生成简单的Python脚本、做数据分析、写前端网页,对吧?这些现在LLM已经能做。那么问题是:我们能不能也做到为GPU编程生成代码?
Jacob Effron:Vibe kernel?
Tri Dao:如果你想要的是这个的话,我觉得我们还处在非常早期的阶段。
这些模型现在能生成一些简单的内核,比如逐元素的操作:你输入一个数组,然后在每个元素上做运算。或者一些归约操作,比如求和、归一化之类的。
这类代码模型能生成得还算不错。但一旦变复杂一些,这些模型就写不出正确的代码了。
我觉得这主要还是因为训练数据不足。
训练数据在这一块非常难搞。因为如果你在网上抓取内核代码,你拿到的可能就是一些课堂项目,或者是GPU三代以前的文档,而这些文档里很多写的都是现在完全不该再用的做法。所以训练数据确实非常困难。我认为答案可能是要从一些专家级的数据开始,然后基于这些生成合成数据。或者把模型接到编译器、性能分析器这样的工具上,从中获得大量训练数据,构建合适的环境。我觉得一两年之内可能会有突破,但目前确实很难。
Jacob Effron:那这些数据现在掌握在谁手里呢?
Tri Dao:我觉得这种数据不算是私有的。
确实有一些地方能找到专家级代码,但更关键的是流程:怎么从少量专家数据出发,生成海量的合成数据。
比如Discord上的GPU Mode社区,他们就在尝试做这个。
他们用编译器,比如PyTorch编译器,把PyTorch代码转换成Triton代码,这个Triton就是更底层的内核代码。
这样他们就能生成大概1.5万对这样的程序数据——PyTorch和Triton的对应关系。
其实你得有点创造性,因为网上原始数据确实不多,所以你得想办法创造训练数据。所以我觉得这是一个方向:如果你想要完全自动化的内核生成,现在还非常早。另一个方向是:模型能不能和人类协同工作?我对这点的惊喜更大——这些模型现在其实已经相当有用了。
Jacob Effron:有没有什么具体的时刻,让你觉得AI模型真的已经有帮助了?
Tri Dao:我觉得大概有两个重要节点。一个是o3——o3的推理能力进步很大。
有时候我会和o3或GPT-5一起头脑风暴,比如我有个函数,该怎么优化?要注意哪些点?
它们给出的高层思路出乎意料地好。
另一个是Claude Code。它居然在写Triton内核方面表现相当不错,这点非常棒。
因为虽然我喜欢写内核,但我更多的时间其实花在设计上:思考该设计怎样的架构,才能更好利用硬件。
而具体的实现部分,虽然设计很有意思,但实现过程往往非常繁重。这时候Claude Code就帮了很大忙。我觉得它能让我整体生产效率提升大约1.5倍。
我是ClaudeCode的重度用户。如果让模型和人类协同工作,而不是指望它们完全自动生成内核,那它们的作用其实非常大。
Jacob Effron:接下来你最期待的里程碑是什么以及新模型出来时,你会测试什么?
Tri Dao:我觉得ClaudeCode是个典型的质变案例,因为它变得更具备代理性了。
某种程度上,他们在后期训练Claude时,针对这一点做得特别好。
我相信OpenAI、Google很快也会达到类似的水平。这里说的代理性(agentic)就是指它能很好地调用工具,并且知道什么时候该用工具。
比如它知道:啊,我现在可能没有用对API,那我要怎么查API?
或者程序没编译过、程序不够快,那我该怎么从profiler里拿信息?就是这种能力。
所以我觉得新模型里,我会关注它们能不能知道自己不知道,以及什么时候该去主动寻找新信息。这虽然听起来有点模糊,但现在已经有人开始做这种代理性能力的基准测试了,只是还非常早期。
Q:自从ChatGPT发布后,这三年到底是什么推动了成本降低和延迟改善?
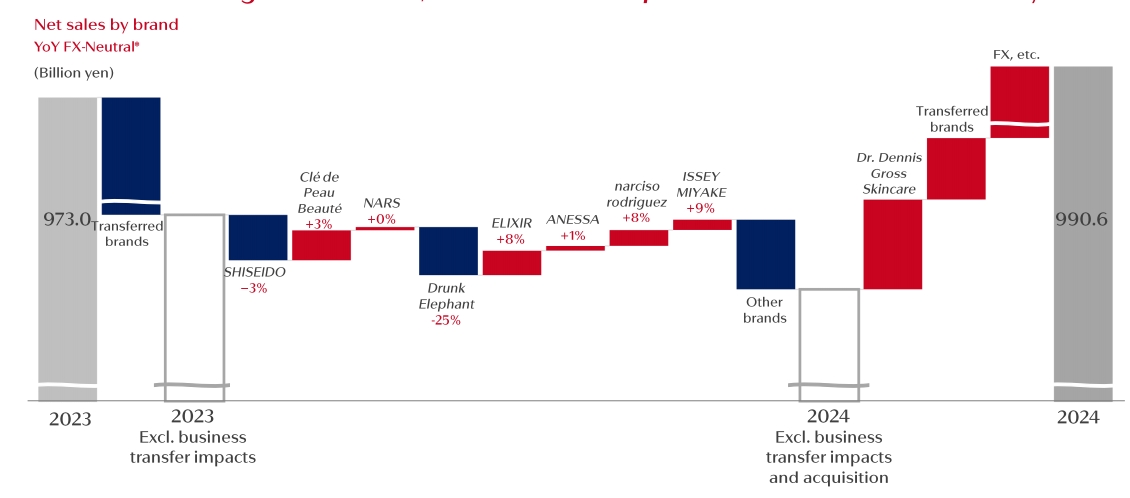
Tri Dao:这几年里,推理成本可能下降了大概100倍
至少从ChatGPT面世以来是这样的,这点从API价格变化上也能反映出来。
一方面是在模型层面,人们在相同参数量级下训练出了更好的模型。
部分原因是使用了更多数据,部分原因是架构改进。我认为MoE确实帮助大家发明了更高效的注意力机制等等。
所以在模型端,模型在相同参数下变得更强大。
另一方面是在推理优化上。
我们见证了一系列技术的大爆发。早期其实大家并不清楚推理的瓶颈在哪里。
后来逐渐发现,关键问题在于数据传输——比如权重在内存之间的搬移,或者KV缓存的搬运。
KV缓存是注意力机制中用于存储历史的部分,以便生成下一个预测。所以大量优化都是围绕如何减少数据搬运展开的。
比如说模型量化
两三年前,通常一个参数需要16位表示。现在8位已经很常见了,新模型里4位也被大量使用,甚至还有1–2位的尝试,非常激进。
但实验显示,在量化过程中,很多情况下质量几乎没有损失。当然这需要相当复杂的技术,但效果非常好。
比如最近OpenAI发布的GPT-oss,大部分层都被量化到4位。他们的模型总共有1200亿参数,但因为每个参数只需4位,整个模型可以放进大概60GB的空间里,这直接转化成了非常好的推理性能。所以量化是一个方向。
另一个方向是模型架构和硬件的协同设计
随着理解的深入,算法研究人员和硬件专家的沟通变多,大家能结合各自的知识去发现硬件上的瓶颈,并针对性地调整算法。
比如Flash Attention就是这样:我们意识到内存访问才是主要瓶颈,于是重新设计了注意力的实现方式,减少内存访问。这类优化在推理领域正在不断发生。
DeepSeek的一个例子叫multi-head latent attention。他们发现推理时很多开销来自于KV缓存的压缩和传输,于是提出通过潜在投影把KV缓存投射到更小的空间,从而大幅减小缓存规模。这在实践中效果很好,能够更高效地部署模型。
还有MixtureofExperts(MoE)。在MoE里,每个token的计算不需要用到模型的所有参数,而是只激活部分专家单元,这就是稀疏化。
在过去两年里,趋势就是让模型越来越稀疏。比如早期Mistral的开源MoE模型是8个专家里激活2个,也就是25%。
而DeepSeek和OpenAI的最新模型里,比如GPT-oss,是在128个专家里只激活4个,也就是1/32。这种稀疏化非常适合大规模服务用户。
总的来说,大家对推理负载的理解更深,模型架构和推理堆栈是协同设计的,这就是最近性能提升的主要来源。
推理优化技术
Q:未来的推理优化技术还会有哪些改进?
Tri Dao:我认为还会有大约10倍的提升空间。
尽管我们已经摘了许多果实,但仍有很多可做的事。
首先是硬件端:过去难以预测两年后的工作负载,所以难以做高度专用化。
但随着架构相对稳定,芯片设计者可以为推理做专门优化,比如加强对低精度的原生硬件支持、改进网络通信等。
特别是在MoE场景下,模型参数增大但每次只激活一部分,模型可能分布在多块GPU/芯片上,这时网络就非常关键。我估计硬件方面一年内就能带来2–3倍的提升。
在模型层面,会有推进架构的空间。
举例我做的Mamba,思路是让模型把历史压缩成更小的状态向量,而不是保存完整的KV cache——这有代价但在某些大批量推理场景下(例如同时探索多条思路的推理或搜索)效果很好。
Google的Gemini Deep Think就是同时探索多路径的思路,这类场景会让KV cache成为更大的瓶颈,因此压缩历史的方向非常重要。我认为模型层面也能带来2–3倍的提升。
在内核实现层面,越来越多人专注于高性能kernel,很多人才正加入这块,内核优化也可能再带来2倍的提升。把这些合起来,短期内一年左右再实现约10倍的整体改进是有可能的
专门化的AI推理
Q:你觉得生态会由单一能覆盖所有场景的供应商主导,还是会出现专门化?
Tri Dao:我认为可能会出现三类工作负载模式,所有推理提供方都会理解并尝试优化这些模式,但规模化也有显著优势。
大体上有:
- 传统聊天机器人:需要一定交互性但不要求极低延迟)极低延迟场景:比如代码辅助,响应快2–3倍能显著提升用户效率——我愿意为此付更多钱以及大规模批处理/高吞吐场景:需要同时对大量序列做推理。
不同供应商可能在这些细分场景上做出不同权衡,有些提供广泛覆盖,有些则专注于某类场景做到极致。我的意思是,人们通过同时运行多个模型来解决这个问题。
比如同时跑四个Claude Code。但我个人更喜欢深度工作,当我和模型合作时,我通常只用一个——我的合作者会骂我,她说:“你应该同时开四个ClaudeCode。”
对这种工作负载,人们可能愿意为低延迟付更多钱,这就是低延迟类型的工作负载。
另一类是非常大批量的工作,我不太在意延迟,只关心尽可能高的吞吐量。这对生成合成数据等场景很重要。
正如我提到的,很多人训练模型的方式是:先有少量专家级数据或人工标注数据。
举个例子,你是一家航空公司,想训练AI助理来处理客户投诉,你手里只有少量高质量数据,然后可以从中生成大量合成数据。模型在模拟人类行为上非常出色。
你可以让模型模拟一个来自纽约、因为航班延误而恼火的顾客,模型竟然能表现得很像人类。
事实上,互联网上就有大量类似数据供模型学习。
模型内部有一套世界模型,它可以基于这些生成大量数据,虽然不如人工数据精准,但量很大。
在这种推理使用场景中,你真正关心的只是吞吐量。
另一类是强化学习训练场景。训练一个智能体执行任务并改变策略时,你需要评估策略的好坏。
这就需要从模型中抽样大量完成结果,也叫rollout,评估其表现。这里就需要大批量、高吞吐的推理能力。我认为这是第三种使用场景——非常大批量。
对于这三类场景,人们已经开始识别这些模式,而作为推理提供方,我们会针对不同场景做不同优化。
Jacob Effron:你们是如何在这三类场景间分配资源的?
Tri Dao:我觉得这就是大规模运行的好处——我们称之为“舰队级优化”。
在数千GPU上推理时,你可以动态调整集群分配。
举个简单例子:运行批量推理(batch API)。
OpenAI提供这个选项,我们也有类似选项。如果看到集群在处理交互式查询时不忙,就可以调入批量查询以充分利用算力。
结果是,我们对batchAPI通常提供约50%折扣,我想OpenAI也是这样,DeepSeek大概也是。
AI工作负载演进与开源工具
Q:你觉得推理市场未来的发展如何?优化空间是否无限?
Tri Dao:过去确实有很多果实,如果你能写出合理内核、搭建合适推理引擎,会比市场上已有方案好很多。
但现在开源工具已经非常成熟了,比如VLMSGLang等项目,都已经达到生产级别质量。
我们也会和这些项目合作、贡献代码。所以基线水平已经提高很多。
同时,工作负载也在不断演化。客户会提出新的需求:前缀缓存、低延迟,或者不是文本而是视频,这些都有不同的性能权衡,我们也在应对这些客户需求。
即便开源工具越来越好,工作负载变化也很快,总有新事情可做。模型本身越来越强,可以从中提取价值的方式也越来越多,这也是为什么有很多初创公司基于这些模型构建业务。工作负载将持续演化。Jacob Effron:快速变化的节奏下,这三大类工作负载会逐渐分化吗?
Tri Dao:我觉得还是会有聚合。代理型(agentic)工作负载可能是杀手级用例。
就像ChatGPT是应用层面的一个跃变,它让用户第一次能与语言模型互动、调试代码、查找和分析信息。
下一波应用将是代理型:AI能自主采取行动、收集信息。这需要不同的优化策略,不只是让模型在GPU上运行得快,还要考虑如何与人类使用的工具衔接,比如Web搜索。
如果是工程师,可能希望模型能访问设计软件;金融分析师,则希望模型能访问特定数据库。这类工作负载预计会成为未来一年左右的主流。
在消费端,我的一个预测是实时视频生成会成为趋势
我们已经看到一些初步迹象,这会像TikTok改变内容消费方式一样,彻底改变消费者体验。我们合作的一些公司,比如Pika LabsHetra,正专注于实时视频生成,这是我们的押注。
实时视频生成也带来全新挑战,非常耗算力,这可能会进一步推动芯片发展和推理优化。
架构创新和专家级别的AI
Q:假如可以快进三年,得到AI基础设施领域一个关键问题的答案,这个问题会是什么?哪一个问题的答案最能影响你们今天的战略?
Tri Dao:接下来几年,我想回答的问题是:我们如何让AI达到专家水平?
目前,我认为模型在某些任务上,比如前端编程,处于人类中等水平。
他们已经很厉害了。实际上,这些模型在前端编程上比我强得多;或者在数据分析这类任务上,只要互联网上有大量数据,模型就能轻松胜任。
它们在这些任务上大概达到了中等水平,甚至略高于平均水平。
但经济上最有价值的任务仍然存在。我们为人类专家支付高额报酬,比如飞机设计、硬件设计、医生、律师等。
这些人成为专家,是因为他们花了大量时间使用专业工具,而这些工具的数据并不等同于互联网海量信息。
这正是他们成为专家的原因。所以我们要让模型达到这个水平,能够与人类专家协同工作,我认为这才是大量经济价值的来源。
Q:你合作者Albert说过,Transformer本身不会是最终方案,你觉得我们需要架构创新才能达到那个水平吗?
Tri Dao:我认为,要达到AGI或ASI,目前的架构可能已经足够了。
但成本如何?如果有更好的架构,也许我们能提前一两年达到目标,或者用10倍更低的成本实现,这可能很值得。
每年我们在AI基础设施上大约花5000亿美元——大概在这个量级。
问题是,我们是否需要花10倍的预算?还是通过更好的架构,用现有甚至更少的支出就能达到目标?
这就是架构研究的价值所在:能否通过更好架构达到AGI。我认为当前架构具备所有关键成分,如果不断扩展,也可以实现目标,但成本可能是天文数字。Jacob Effron:你还在关注哪些架构?
Tri Dao:我对MoE特别感兴趣,尤其是越来越稀疏。我们在探索极限:能稀疏到什么程度?
这一直是一个很有吸引力的方向。DeepSeek做了很重要的工作,证明可以让模型非常稀疏,DeepMind早期也有相关探索。这是一种用同样算力获得更多智能的方法。
最终,我们想优化每分钱的推理效率。
这意味着可以量化为每浮点操作推理量(inference per flop)和每分钱的FLOPs。
前者更多依赖架构设计、数据、算法;后者更多依赖硬件和内核优化。在架构层面,我们尝试从相同计算中提取尽可能多的智能。MoE是一个例子。
我和Albert做的一些状态空间模型工作也很有趣。
我们与Nvidia的一些团队合作训练模型,他们发布了几款模型,显示这种架构——Transformer与Mamba的混合——可以在更低成本或更高推理性能下得到高质量模型。
所以架构对于推理非常重要。我现在非常强调“推理优先”的架构设计,因为大部分FLOPs都用于推理,我们希望架构能最大化推理效率。
Jacob Effron:你现在在研究哪些方向?未来可能有哪些重要论文?
Tri Dao:我仍然在这些领域工作,非常感兴趣。同时,我也在探索一些新方向,其中之一是寻找下一波真正有影响力的应用。我认为机器人是其中一个方向。
比如离真正优秀的家庭人形机器人还有多远?
也许五年,也许十年,我不确定。这通常会带来很多有趣且重要的研究问题,这是科研方向上的一个方向。
Jacob Effron:在机器人研究领域,你觉得最有趣的点是什么?
Tri Dao:关于机器人,我们可以用已有的基础模型来初始化控制机器人。你可以用语言模型来做规划。
比如,你让机器人去拿咖啡杯,语言模型可以说:“去那张桌子拿咖啡杯”,等等。
但目前缺失的是在现实世界中进行交互和行动的数据,因为我们没有这类数据。我们有语言数据,但缺少与实际世界交互的数据。对,你显然也看到有人在尝试扩大仿真数据的规模,他们实际上在做遥操作,但实际波动的数据问题依然存在。
另一点是,机器人必须以多分辨率、多时间尺度的方式处理信息。有些操作,比如控制关节,需要非常快速的响应;但规划机器人的路径,则可以慢一些。
这里需要显式考虑时间尺度。我想做非常轻量的计算吗?只是控制关节,还是做更重的推理来规划最优路径?
所以我认为最终会是一个复合系统,由语言模型、视觉模型、音频模型、世界模型初始化,但如何把它们组合在一起,是一个大问题。
学术界与工业界的平衡
Q:你是如何考虑在学术和工业之间的选择的?
Tri Dao:这是个很好的问题,也很个人化。对我来说,我喜欢同时做创业和做教授。
这两种模式提供了不同的思维和执行方式。创业方面很有趣,因为节奏快。我们想做的事情,几天、几周、最多几个月就能完成。团队执行力强,可以快速实现目标,我对团队在Together做的工作非常自豪。
学术方面,时间尺度更长,考虑的问题更具前瞻性。我们不会追求一个月内的解决方案,而是思考未来两三年方向上的有趣问题和挑战。和学生一起工作也非常有趣,因为我们可以深入思考这些问题。
当然有一些权衡,比如学术计算资源少。评价方式也不同,更关注思想是否有趣,而不是是否运行得快。
学术给你更多自由去深入思考长周期问题。我正好喜欢两种模式,所以仍然在普林斯顿做教授,同时参与创业。
我认为这是一种探索与开发结合的模式:学术更偏向探索,资金通常来自政府,用于探索大量想法,也许只有5-10%的想法会成功。投资者也类似,探索大量想法,其中少数可能非常重要。
一个例子是Attention,它通过Google的论文出名,但最初来自Mila的学术研究,是Dmitry Bahdanau、Yoshua Bengio等人的工作。
当前架构的其他组成部分,如Adam优化器(JimmieBa等)和LayerNorm,也来自学术界。
很多现在的基础都是学术探索的结果。大公司和创业公司会把这些想法商业化,快速执行,同时理解市场需求,有更多资金推动大想法落地。
比如,SSI明确说不做任何产品,但人们愿意投钱,因为他是Ilya。当AI的某些风投开始获得回报,投资者就更愿意投入资金。
Jacob Effron:过去一年你在AI上改变的一个观点是什么?
Tri Dao:这些模型出乎意料地有用,即便在常的高级和专家级工作中,它们在数学和编码上也非常出色。比我预期的高很多,确实很厉害。
我日
Jacob Effron:你觉得一年后开源模型和闭源模型的质量会更接近还是更远?我认为会更接近。现在的扩展更多依赖RL,而这实际上更依赖工具链,而不仅仅是原始算力。所以开源在这方面会做得很好。
Jacob Effron:目前AI领域还有哪些发展被忽视了?
Tri D:数据。数据总是有点被低估。合成数据,用模型重新生成或改写数据,会产生巨大影响,但关注的人少。Jacob Effron:你最喜欢看到的应用是什么?
Tri Dao:我们与一些视频生成公司合作,比如Pika Labs和Hetra,他们用我们训练的模型生成虚拟的TikTok视频,效果非常棒。
更新内容
一、修复bug,修改自动播放;优化产品用户体验。
二、 1.修复已知Bug。2.新服务。
三、修复已知bug;优化用户体验
四、1,交互全面优化,用户操作更加便捷高效;2,主题色更新,界面风格更加协调;3,增加卡片类个人数据
五、-千万商品随意挑选,大图展现商品细节-订单和物流查询实时同步-支持团购和名品特卖,更有手机专享等你抢-支付宝和银联多种支付方式,轻松下单,快捷支付-新浪微博,支付宝,QQ登录,不用注册也能购物-支持商品收藏,随时查询喜爱的商品和历史购物清单。
六、1.bug修复,提升用户体验;2.优化加载,体验更流程;3.提升安卓系统兼容性
七、1、修复部分机型bug;2、提高游戏流畅度;
厂商其他下载
安卓应用 安卓手游 苹果应用 苹果手游 电脑 更多+
-
 田栩宁白衬衫少年感
田栩宁白衬衫少年感
-
 陈楚生 夕阳是月光的伏笔
陈楚生 夕阳是月光的伏笔
-
 明知前方路很堵 也要踏上这条路
明知前方路很堵 也要踏上这条路
-
 茶叶蛋是哪个天才想出来的
茶叶蛋是哪个天才想出来的
-
 许妍被骗子好友讹上了
许妍被骗子好友讹上了
-
 成龙孙楠肖战王力宏容祖儿合照
成龙孙楠肖战王力宏容祖儿合照
-
 上大学真的可以改变一个人
上大学真的可以改变一个人
-
 少数民族如何过中秋
少数民族如何过中秋
-
 曾舜晞这跟表白有什么区别
曾舜晞这跟表白有什么区别
-
 辣辣连麦老二
辣辣连麦老二
-
 乱港分子罗冠聪入境新加坡被拘
乱港分子罗冠聪入境新加坡被拘
-
 王源三巡送出近百万奖品
王源三巡送出近百万奖品
-
 沈佳润 一点垫音混音不给孩子加
沈佳润 一点垫音混音不给孩子加
-
 宋亚轩在王牌的抽象上不封顶
宋亚轩在王牌的抽象上不封顶
-
 假期的前两天比假期里还要让人愉悦
假期的前两天比假期里还要让人愉悦
-
 假期出行健康事项哪些要注意
假期出行健康事项哪些要注意
-
 韩红说林俊杰为了做公益刘海都不吹
韩红说林俊杰为了做公益刘海都不吹
-
 专家:中国提前规划美国被动反应
专家:中国提前规划美国被动反应
-
 崔胜澈 让JYP从你身体里出去
崔胜澈 让JYP从你身体里出去
-
 漂亮的妈 争气的娃
漂亮的妈 争气的娃
相关版本
- 中文名:Flash Attention作者最新播客:英伟达GPU统治三年内将终结
- 包名:com.ejiaqrp.dtgen
- MD5:P7ENQIWOC1RTO1T6EP
查看所有 0条评论>网友评论
- 相关游戏
-
 迪丽热巴chill车站大片
迪丽热巴chill车站大片
 欧阳澄汐萌版柠檬叉angel
欧阳澄汐萌版柠檬叉angel
 宴遇永安定档
宴遇永安定档
 熊出没演我国庆放假
熊出没演我国庆放假
 小沈阳和女儿惊喜同台
小沈阳和女儿惊喜同台
 外交部回应台当局派员窜访有关国家
外交部回应台当局派员窜访有关国家
 双节假期这3条高速充电桩最繁忙
双节假期这3条高速充电桩最繁忙
 丁程鑫赢了原相机
丁程鑫赢了原相机
 李立群入驻快手
李立群入驻快手
 和陈伯合唱有点甜
和陈伯合唱有点甜
 锤娜丽莎你的权威我后知后觉
锤娜丽莎你的权威我后知后觉
 刘昊然推荐河南美食胡辣汤
刘昊然推荐河南美食胡辣汤
 距离全国餐饮人的噩梦还剩1天
距离全国餐饮人的噩梦还剩1天
 鸡排哥1分钟视频报价仅10元
鸡排哥1分钟视频报价仅10元
 哈皮杯S2正赛
哈皮杯S2正赛
 没钱旅游去参加躺平大赛
没钱旅游去参加躺平大赛
 哈马斯成员钻出地道突袭以军营地
哈马斯成员钻出地道突袭以军营地
 不要吃蓝色臭豆腐
不要吃蓝色臭豆腐
 方益炯手绘徐如蓝心动瞬间
方益炯手绘徐如蓝心动瞬间
 小猫在河南真的坏事做尽
小猫在河南真的坏事做尽
 王健林“限高”措施已取消
王健林“限高”措施已取消
 中秋六不摆
中秋六不摆
 最好的祝福送给祖国
最好的祝福送给祖国
 解放军潜艇部队配鹰击-19有多强
解放军潜艇部队配鹰击-19有多强
 黄子弘凡的荧光棒砸到谁了
黄子弘凡的荧光棒砸到谁了
 颜安余宇涵好吵的两个人
颜安余宇涵好吵的两个人
 中共中央政治局9月29日召开会议
中共中央政治局9月29日召开会议
 小酒窝追星成功
小酒窝追星成功
 内娱最会吻的cp上新了
内娱最会吻的cp上新了
 王勉这秀球技术能让人唠一辈子
王勉这秀球技术能让人唠一辈子
 闫妮魏大勋微醺加倍
闫妮魏大勋微醺加倍
 向佐回应向家破产传闻
向佐回应向家破产传闻
 湘 我在外面很想你
湘 我在外面很想你
 赴山海
赴山海
 今年的国庆中秋少了几天假
今年的国庆中秋少了几天假
 爱奇艺尖叫之夜阵容
爱奇艺尖叫之夜阵容
 没想到高速上都是聪明人
没想到高速上都是聪明人
 闫妮又微醺了
闫妮又微醺了
 外国人被中国超市震惊
外国人被中国超市震惊
 没想到高速上都是聪明人
没想到高速上都是聪明人
- 更多>心动网络手游
-
 人 国庆打算干什么
人 国庆打算干什么
 11人死刑 缅北明家犯罪集团案宣判
11人死刑 缅北明家犯罪集团案宣判
 萝北18米巨幅国旗庆祝祖国华诞
萝北18米巨幅国旗庆祝祖国华诞
 勇敢小铁挑战
勇敢小铁挑战
 特朗普召集美军将领开会有何意味
特朗普召集美军将领开会有何意味
 用押韵的方式打开这个白敬亭
用押韵的方式打开这个白敬亭
 鞠婧祎早上六点录的醒瞌睡舞
鞠婧祎早上六点录的醒瞌睡舞
 新一任党主席如何提升国民党战斗力
新一任党主席如何提升国民党战斗力
 长期喝茶和长期喝白开水的身体差异
长期喝茶和长期喝白开水的身体差异
 小沈阳回应“被抬走”
小沈阳回应“被抬走”
 赴山海
赴山海
 吴晙诚3比2邱党
吴晙诚3比2邱党
 合作方曝王一博有严重的高反
合作方曝王一博有严重的高反
 小猫在河南真的坏事做尽
小猫在河南真的坏事做尽
 丝芭传媒起诉解约成员
丝芭传媒起诉解约成员
 林志炫没离开过杀回来了
林志炫没离开过杀回来了
 全国各地都飘起中国红
全国各地都飘起中国红
 这三个“最” 凸显治水成绩单含金量
这三个“最” 凸显治水成绩单含金量
 小酒窝发博
小酒窝发博
 妈妈因儿子成绩“三连跌”怒退机票
妈妈因儿子成绩“三连跌”怒退机票
 大学生“手搓”机械战甲
大学生“手搓”机械战甲
 王健林的限高为什么一夜之间取消
王健林的限高为什么一夜之间取消
 贵州各式特色粑粑等你来
贵州各式特色粑粑等你来
 小沈阳和女儿惊喜同台
小沈阳和女儿惊喜同台
 陈闲分手了
陈闲分手了
 罗予彤的底气是哥哥给的
罗予彤的底气是哥哥给的
 蟋蟀成月饼馅 广东人:蟑螂馅不远了
蟋蟀成月饼馅 广东人:蟑螂馅不远了
 小米17系列首发评测
小米17系列首发评测
 你们是怎么说服让他当年糕的
你们是怎么说服让他当年糕的
 肖战容祖儿 这是小沈阳的女儿
肖战容祖儿 这是小沈阳的女儿
 男子回家遇到退休的小学老师
男子回家遇到退休的小学老师
 隔壁老樊回应看王楚钦比赛
隔壁老樊回应看王楚钦比赛
 上两天班就到假期了
上两天班就到假期了
 这三个“最” 凸显治水成绩单含金量
这三个“最” 凸显治水成绩单含金量
 薛凯五角星光迎国庆
薛凯五角星光迎国庆
 王栎鑫前手翻童子功
王栎鑫前手翻童子功
 KPL北京WB vs 桐乡情久
KPL北京WB vs 桐乡情久
 严浩翔眉骨接彩带
严浩翔眉骨接彩带
 新华社为肖战编辑了8次
新华社为肖战编辑了8次
 本来想减肥的
本来想减肥的
- 更多>mod游戏
-
 此沙五套风衣
此沙五套风衣
 闫妮演我国庆放假前上班精神状态
闫妮演我国庆放假前上班精神状态
 动物性太强的人不要深交
动物性太强的人不要深交
 六小龄童被猴王包围
六小龄童被猴王包围
 许我耀眼的带货能力
许我耀眼的带货能力
 波兰五星级酒店的拖鞋
波兰五星级酒店的拖鞋
 缅北明家主案宣判 11人获死刑
缅北明家主案宣判 11人获死刑
 S15世界赛前瞻
S15世界赛前瞻
 肖战婉拒签名
肖战婉拒签名
 股民晒十年前买的两只股票收益
股民晒十年前买的两只股票收益
 四川小厨娘变身
四川小厨娘变身
 王蓉蒋一侨谭薇郑湫泓组新女团
王蓉蒋一侨谭薇郑湫泓组新女团
 本来想减肥的
本来想减肥的
 乘客将9元车费误转成9万 司机报警
乘客将9元车费误转成9万 司机报警
 考古真正男子汉都是名场面
考古真正男子汉都是名场面
 漂亮的妈 争气的娃
漂亮的妈 争气的娃
 孙颖莎拉伸训练细节太到位
孙颖莎拉伸训练细节太到位
 女子高铁说讨厌小孩被宝妈怼哭
女子高铁说讨厌小孩被宝妈怼哭
 金饰克价突破1110元
金饰克价突破1110元
 王楚钦入选全国体育系统先进个人
王楚钦入选全国体育系统先进个人
 中方敦促有关国家与“台独”划清界限
乱港分子罗冠聪入境新加坡被拘
中方敦促有关国家与“台独”划清界限
乱港分子罗冠聪入境新加坡被拘
 赛场闪光灯影响球员你怎么看
赛场闪光灯影响球员你怎么看
 四川小厨娘变身
四川小厨娘变身
 刘天池透露辛柏青近况
刘天池透露辛柏青近况
 鸡排哥文旅座谈会上发言
鸡排哥文旅座谈会上发言
 景德镇鸡排哥大揭秘
景德镇鸡排哥大揭秘
 受贿3.57亿 贵阳前市长陈晏被判死缓
受贿3.57亿 贵阳前市长陈晏被判死缓
 徐振轩 萌力值拉满
徐振轩 萌力值拉满
 宴遇永安定档
宴遇永安定档
 常回家看看主唱陈红被前夫举报
常回家看看主唱陈红被前夫举报
 余宇涵 妈妈不用担心你吃不饱饭了
余宇涵 妈妈不用担心你吃不饱饭了
 张晚意骑骆驼迷死我了
张晚意骑骆驼迷死我了
 陈楚生 夕阳是月光的伏笔
陈楚生 夕阳是月光的伏笔
 黄灿灿笔下的大学是我梦想的青春
黄灿灿笔下的大学是我梦想的青春
 技能五子棋笑点在哪
技能五子棋笑点在哪
 官方辟谣工人掉进月饼机被做成月饼
官方辟谣工人掉进月饼机被做成月饼
 心力受损 长胖
心力受损 长胖
 内娱最会吻的cp上新了
内娱最会吻的cp上新了
 赵丽颖心情调成暖调
赵丽颖心情调成暖调
- 更多>像素rpg游戏
-
 丁程鑫刺杀小说家2首映礼生图
丁程鑫刺杀小说家2首映礼生图
 腾讯客服回应朋友圈照片变清晰
腾讯客服回应朋友圈照片变清晰
 T1包揽LCK收视率前五
T1包揽LCK收视率前五
 米兰街头的张婧仪
米兰街头的张婧仪
 这三个“最” 凸显治水成绩单含金量
这三个“最” 凸显治水成绩单含金量
 RED湾区升明月中国话舞台
RED湾区升明月中国话舞台
 不要吃蓝色臭豆腐
不要吃蓝色臭豆腐
 王曼昱霸气手指观众席闪光灯
王曼昱霸气手指观众席闪光灯
 肖战火热开场全场沸腾
肖战火热开场全场沸腾
 颜安内娱独一份抽象
颜安内娱独一份抽象
 小猫在河南真的坏事做尽
小猫在河南真的坏事做尽
 英皇老板和肖战合照
英皇老板和肖战合照
 马丁染黑发了
马丁染黑发了
 张婧仪米兰街头路透
张婧仪米兰街头路透
 张子枫也到了彭昱畅来向往的年纪
张子枫也到了彭昱畅来向往的年纪
 雨果:国乒年轻球员缺乏统治力
雨果:国乒年轻球员缺乏统治力
 闫妮与魏大勋合唱Mojito
闫妮与魏大勋合唱Mojito
 UP主租下机场整活评车
UP主租下机场整活评车
 广东湛江多地现龙卷风白浪直扑岸边
广东湛江多地现龙卷风白浪直扑岸边
 佟丽娅带小酒窝找宋亚轩打招呼
佟丽娅带小酒窝找宋亚轩打招呼
 我必须要活下去的理由
我必须要活下去的理由
 K字签证在印度引发关注 中方回应
K字签证在印度引发关注 中方回应
 张婧仪米兰街头路透
张婧仪米兰街头路透
 听妈妈话的孙红雷
听妈妈话的孙红雷
 食物不可能三角
食物不可能三角
 马思纯文艺感
马思纯文艺感
 舞者解晓东去世
舞者解晓东去世
 模具不语 只是一味压汉堡月饼
模具不语 只是一味压汉堡月饼
 KPL杭州LGD.NBW零封济南RW侠
KPL杭州LGD.NBW零封济南RW侠
 开始跳舞吧少年们为了最后的方巾拼了
开始跳舞吧少年们为了最后的方巾拼了
 电影志愿军拍出课本里的黄继光
电影志愿军拍出课本里的黄继光
 张凌赫演我吃月饼
张凌赫演我吃月饼
 被单身三十年的霸总爱上是什么体验
被单身三十年的霸总爱上是什么体验
 天坑溶洞垃圾10层楼高 当地通报
天坑溶洞垃圾10层楼高 当地通报
 明道大湾区晚会童年回忆杀
明道大湾区晚会童年回忆杀
 沈佳润应邀来的小沈阳硬要来的
沈佳润应邀来的小沈阳硬要来的
 赴山海
赴山海
 那些让人意难平的电影结尾
那些让人意难平的电影结尾
 许我耀眼许妍MVP结算画面
许我耀眼许妍MVP结算画面
 发现身边的手艺人
发现身边的手艺人
-
2025-09-29
1

-
2025-09-29
2

-
2025-09-29
3
-
2025-09-29
4

-
2025-09-29
5

-
2025-09-29
6
-
2025-09-29
7

-
2025-09-29
8

-
2025-09-29
9

-
2025-09-29
10

-
2025-09-29
11

-
2025-09-29
12

-
2025-09-29
13

-
2025-09-29
14

-
2025-09-29
15

-
2025-09-29
16

-
2025-09-29
17

-
2025-09-29
18

-
2025-09-29
19

-
2025-09-29
20

-
2025-09-29
21

-
2025-09-29
22

-
2025-09-29
23

-
2025-09-29
24

-
2025-09-29
25

-
2025-09-29
26

-
2025-09-29
27

-
2025-09-29
28
-
2025-09-29
29

-
2025-09-29
30

-
2025-09-29
31

-
2025-09-29
32

-
2025-09-29
33

-
2025-09-29
34

-
2025-09-29
35

-
2025-09-29
36

-
2025-09-29
37

-
2025-09-29
38

-
2025-09-29
39

-
2025-09-29
40

-
2025-09-29
41

-
2025-09-29
42

-
2025-09-29
43

-
2025-09-29
44

-
2025-09-29
45

-
2025-09-29
46

-
2025-09-29
47

-
2025-09-29
48

-
2025-09-29
49

-
2025-09-29
50
-
2025-09-29
51

-
2025-09-29
52

-
2025-09-29
53

-
2025-09-29
54

-
2025-09-29
55

-
2025-09-29
56

-
2025-09-29
57

-
2025-09-29
58

-
2025-09-29
59

-
2025-09-29
60
-
2025-09-29
61

-
2025-09-29
62

-
2025-09-29
63
-
2025-09-29
64

-
2025-09-29
65

-
2025-09-29
66

-
2025-09-29
67

-
2025-09-29
68

-
2025-09-29
69

-
2025-09-29
70

-
2025-09-29
71

-
2025-09-29
72

-
2025-09-29
73
-
2025-09-29
74

-
2025-09-29
75

-
2025-09-29
76

-
2025-09-29
77

-
2025-09-29
78

-
2025-09-29
79

-
2025-09-29
80

-
2025-09-29
81

-
2025-09-29
82

-
2025-09-29
83

-
2025-09-29
84

-
2025-09-29
85

-
2025-09-29
86

-
2025-09-29
87

-
2025-09-29
88

-
2025-09-29
89

-
2025-09-29
90

-
2025-09-29
91

-
2025-09-29
92

-
2025-09-29
93

-
2025-09-29
94
-
2025-09-29
95

-
2025-09-29
96

-
2025-09-29
97

-
2025-09-29
98

-
2025-09-29
99

-
2025-09-29
100

-
2025-09-29
101
-
2025-09-29
102

-
2025-09-29
103

-
2025-09-29
104

-
2025-09-29
105

-
2025-09-29
106

-
2025-09-29
107

-
2025-09-29
108

-
2025-09-29
109
-
2025-09-29
110

-
2025-09-29
111

-
2025-09-29
112

-
2025-09-29
113
-
2025-09-29
114
-
2025-09-29
115
-
2025-09-29
116

-
2025-09-29
117

-
2025-09-29
118

-
2025-09-29
119

-
2025-09-29
120
-
2025-09-29
121

-
2025-09-29
122

-
2025-09-29
123

-
2025-09-29
124

-
2025-09-29
125

-
2025-09-29
126

-
2025-09-29
127
-
2025-09-29
128

-
2025-09-29
129

-
2025-09-29
130

-
2025-09-29
131

-
2025-09-29
132

-
2025-09-29
133

-
2025-09-29
134
-
2025-09-29
135

-
2025-09-29
136

-
2025-09-29
137

-
2025-09-29
138

-
2025-09-29
139

-
2025-09-29
140
-
2025-09-29
141

-
2025-09-29
142

-
2025-09-29
143

-
2025-09-29
144

-
2025-09-29
145

-
2025-09-29
146

-
2025-09-29
147

-
2025-09-29
148

-
2025-09-29
149

-
2025-09-29
150
-
2025-09-29
151

-
2025-09-29
152

-
2025-09-29
153
-
2025-09-29
154

-
2025-09-29
155
-
2025-09-29
156

-
2025-09-29
157

-
2025-09-29
158

-
2025-09-29
159

-
2025-09-29
160

-
2025-09-29
161

-
2025-09-29
162

-
2025-09-29
163

-
2025-09-29
164

-
2025-09-29
165

-
2025-09-29
166
-
2025-09-29
167

-
2025-09-29
168

-
2025-09-29
169

-
2025-09-29
170

-
2025-09-29
171

-
2025-09-29
172

-
2025-09-29
173

-
2025-09-29
174

-
2025-09-29
175

-
2025-09-29
176

-
2025-09-29
177

-
2025-09-29
178

-
2025-09-29
179

-
2025-09-29
180

-
2025-09-29
181

-
2025-09-29
182

-
2025-09-29
183

-
2025-09-29
184

-
2025-09-29
185

-
2025-09-29
186

-
2025-09-29
187

-
2025-09-29
188

-
2025-09-29
189

-
2025-09-29
190

-
2025-09-29
191

-
2025-09-29
192

-
2025-09-29
193

-
2025-09-29
194

-
2025-09-29
195

-
2025-09-29
196
-
2025-09-29
197

-
2025-09-29
198

-
2025-09-29
199

-
2025-09-29
200

-
2025-09-29
201

-
2025-09-29
202
-
2025-09-29
203

-
2025-09-29
204

-
2025-09-29
205

-
2025-09-29
206

-
2025-09-29
207

-
2025-09-29
208

-
2025-09-29
209

-
2025-09-29
210

-
2025-09-29
211

-
2025-09-29
212

-
2025-09-29
213

-
2025-09-29
214

-
2025-09-29
215

-
2025-09-29
216

-
2025-09-29
217

-
2025-09-29
218

-
2025-09-29
219

-
2025-09-29
220

-
2025-09-29
221
-
2025-09-29
222

-
2025-09-29
223

-
2025-09-29
224

-
2025-09-29
225

-
2025-09-29
226

-
2025-09-29
227

-
2025-09-29
228

-
2025-09-29
229

-
2025-09-29
230

-
2025-09-29
231

-
2025-09-29
232

-
2025-09-29
233

-
2025-09-29
234

-
2025-09-29
235

-
2025-09-29
236

-
2025-09-29
237

-
2025-09-29
238

-
2025-09-29
239

-
2025-09-29
240

-
2025-09-29
241

-
2025-09-29
242

-
2025-09-29
243

-
2025-09-29
244

-
2025-09-29
245

-
2025-09-29
246

-
2025-09-29
247

-
2025-09-29
248

-
2025-09-29
249

-
2025-09-29
250

-
2025-09-29
251

-
2025-09-29
252

-
2025-09-29
253

-
2025-09-29
254

-
2025-09-29
255

-
2025-09-29
256

-
2025-09-29
257

-
2025-09-29
258
-
2025-09-29
259

-
2025-09-29
260

-
2025-09-29
261

-
2025-09-29
262

-
2025-09-29
263

-
2025-09-29
264

-
2025-09-29
265

-
2025-09-29
266

-
2025-09-29
267

-
2025-09-29
268

-
2025-09-29
269

-
2025-09-29
270

-
2025-09-29
271

-
2025-09-29
272

-
2025-09-29
273

-
2025-09-29
274

-
2025-09-29
275

-
2025-09-29
276

-
2025-09-29
277

-
2025-09-29
278

-
2025-09-29
279
-
2025-09-29
280

-
2025-09-29
281
-
2025-09-29
282

-
2025-09-29
283

-
2025-09-29
284

-
2025-09-29
285

-
2025-09-29
286

-
2025-09-29
287

-
2025-09-29
288

-
2025-09-29
289

-
2025-09-29
290

-
2025-09-29
291

-
2025-09-29
292

-
2025-09-29
293

-
2025-09-29
294

-
2025-09-29
295

-
2025-09-29
296

-
2025-09-29
297

-
2025-09-29
298

-
2025-09-29
299

-
2025-09-29
300

-
2025-09-29
301
-
2025-09-29
302

-
2025-09-29
303

-
2025-09-29
304

-
2025-09-29
305

-
2025-09-29
306

-
2025-09-29
307

-
2025-09-29
308

-
2025-09-29
309

-
2025-09-29
310

-
2025-09-29
311

-
2025-09-29
312

-
2025-09-29
313

-
2025-09-29
314

-
2025-09-29
315

-
2025-09-29
316

-
2025-09-29
317

-
2025-09-29
318

-
2025-09-29
319

-
2025-09-29
320

-
2025-09-29
321

-
2025-09-29
322

-
2025-09-29
323

-
2025-09-29
324

-
2025-09-29
325

-
2025-09-29
326

-
2025-09-29
327

-
2025-09-29
328

-
2025-09-29
329

-
2025-09-29
330

-
2025-09-29
331

-
2025-09-29
332

-
2025-09-29
333

-
2025-09-29
334
-
2025-09-29
335

-
2025-09-29
336

-
2025-09-29
337
-
2025-09-29
338

-
2025-09-29
339

-
2025-09-29
340
-
2025-09-29
341

-
2025-09-29
342

-
2025-09-29
343

-
2025-09-29
344

-
2025-09-29
345

-
2025-09-29
346

-
2025-09-29
347

-
2025-09-29
348

-
2025-09-29
349

-
2025-09-29
350

-
2025-09-29
351

-
2025-09-29
352

-
2025-09-29
353
-
2025-09-29
354

-
2025-09-29
355

-
2025-09-29
356

-
2025-09-29
357

-
2025-09-29
358

-
2025-09-29
359

-
2025-09-29
360

-
2025-09-29
361

-
2025-09-29
362

-
2025-09-29
363

-
2025-09-29
364

-
2025-09-29
365

-
2025-09-29
366

-
2025-09-29
367

-
2025-09-29
368

-
2025-09-29
369
-
2025-09-29
370

-
2025-09-29
371

-
2025-09-29
372

-
2025-09-29
373
-
2025-09-29
374

-
2025-09-29
375

-
2025-09-29
376

-
2025-09-29
377
-
2025-09-29
378

-
2025-09-29
379

-
2025-09-29
380

-
2025-09-29
381

-
2025-09-29
382

-
2025-09-29
383

-
2025-09-29
384

-
2025-09-29
385

-
2025-09-29
386

-
2025-09-29
387

-
2025-09-29
388

-
2025-09-29
389

-
2025-09-29
390

-
2025-09-29
391

-
2025-09-29
392

-
2025-09-29
393

-
2025-09-29
394

-
2025-09-29
395

-
2025-09-29
396
-
2025-09-29
397
-
2025-09-29
398

-
2025-09-29
399

-
2025-09-29
400

-
2025-09-29
1
-
2025-09-29
2

-
2025-09-29
3

-
2025-09-29
4
-
2025-09-29
5

-
2025-09-29
6

-
2025-09-29
7
-
2025-09-29
8

-
2025-09-29
9

-
2025-09-29
10

-
2025-09-29
11

-
2025-09-29
12
-
2025-09-29
13

-
2025-09-29
14

-
2025-09-29
15

-
2025-09-29
16

-
2025-09-29
17

-
2025-09-29
18

-
2025-09-29
19

-
2025-09-29
20
-
2025-09-29
21

-
2025-09-29
22

-
2025-09-29
23

-
2025-09-29
24

-
2025-09-29
25

-
2025-09-29
26

-
2025-09-29
27

-
2025-09-29
28

-
2025-09-29
29

-
2025-09-29
30

-
2025-09-29
31

-
2025-09-29
32

-
2025-09-29
33

-
2025-09-29
34

-
2025-09-29
35

-
2025-09-29
36

-
2025-09-29
37

-
2025-09-29
38

-
2025-09-29
39

-
2025-09-29
40

-
2025-09-29
41

-
2025-09-29
42

-
2025-09-29
43

-
2025-09-29
44

-
2025-09-29
45

-
2025-09-29
46

-
2025-09-29
47

-
2025-09-29
48

-
2025-09-29
49

-
2025-09-29
50

-
2025-09-29
51

-
2025-09-29
52

-
2025-09-29
53

-
2025-09-29
54

-
2025-09-29
55

-
2025-09-29
56

-
2025-09-29
57

-
2025-09-29
58
-
2025-09-29
59
-
2025-09-29
60

-
2025-09-29
61
-
2025-09-29
62

-
2025-09-29
63

-
2025-09-29
64

-
2025-09-29
65

-
2025-09-29
66

-
2025-09-29
67

-
2025-09-29
68

-
2025-09-29
69

-
2025-09-29
70

-
2025-09-29
71

-
2025-09-29
72

-
2025-09-29
73

-
2025-09-29
74

-
2025-09-29
75

-
2025-09-29
76

-
2025-09-29
77

-
2025-09-29
78

-
2025-09-29
79

-
2025-09-29
80

-
2025-09-29
81

-
2025-09-29
82

-
2025-09-29
83
-
2025-09-29
84

-
2025-09-29
85

-
2025-09-29
86

-
2025-09-29
87

-
2025-09-29
88

-
2025-09-29
89

-
2025-09-29
90

-
2025-09-29
91

-
2025-09-29
92

-
2025-09-29
93

-
2025-09-29
94

-
2025-09-29
95

-
2025-09-29
96

-
2025-09-29
97

-
2025-09-29
98

-
2025-09-29
99

-
2025-09-29
100

